有时候会遇到一些数据是乱码,这是都是由于数据编码的问题导致的
众所周知,电脑是识别不了语言的,只能处理0和1的字符串,于是这个时候就需要将这些0和1转化为字符,这个过程就是编码。
首先我们在看编码过程中我们要知道十六进制就是二进制,4个二进制对应1个十六进制,通常我们在说A为0100 0001(二进制)时表示为A为41(十六进制)
ASCII编码
在电脑最先出来是在美国,当时在他们的世界里中有a b c…这样的字符。于是他们规定的编码方式只包含了他们所使用的字符(也就是我们现在所说的ascii编码)。比如ABC DEF编码如下:
(每一个字符对应一个数字)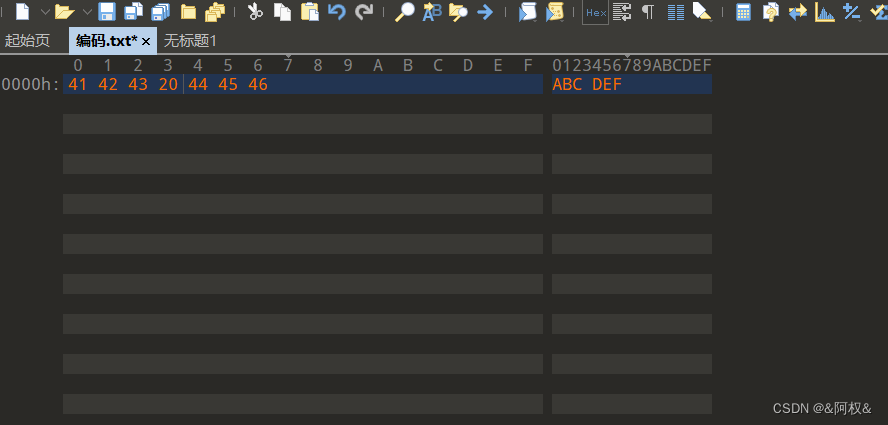
GBK和Big5编码
当电脑在全世界传播时,发现每个国家所使用的字符不同,如果只使用ascii码将无法满足各个地区的需求,于是这个时候就出现了big5和GBK编码。
GBK编码:是我们国内所使用的一种,包含GBK2312等编码。为了将我们的汉字也加入编码中,于是人们在ascii码的基础上进行了扩展,采用了两个字节表示一个汉字
阿 权—>B0A2 C8A8
Big5编码:同时一些地方为了满足他们的要求,就出现了big5编码,同样采用了两个字节表示一个字符
此时还诞生了一些其他的编码。
unicode编码
但是再后来,当不同地区的人传输数据时,由于采用的编码形式不同,于是就出现了乱码。为了解决这个问题,就出现了unicode。Unicode为了满足所有人的需求,就将所有的字符收录,并且规定了一个对应的等长的二进制数。0x0000 - 0x10FFFF 每个字母对应一个数字。
但是比较特殊的是unicode只是规定了如何编码,具体的实现需要utf-8,utf-16来实现。
比如Utf-8:因为unicode是等长的编码,传输起来会占据很多空间,UTF-8的特点是对不同范围的字符使用不同长度的编码。
我们遇到的乱码,基本上就是由于你所使用的编码方式和文件的编码方式不同