前言
Bit,Byte,word都是多大内存,给你一个数字,字母,汉字,他到底在内存中占据多少内存?对于刚接触这些的来说,整个人都是晕的。我们每次所接触到的都是MB,KB,GB,对这些底层问题是一点也不清楚。
首先,我们需要知道的是在底层中只有三个单位,bit(位),byte(字节),word(字)。
bit(位)是最小的单位
计算机处理的数据都是一段逻辑0和1的字符串,于是一个逻辑0或1占据的内存为最小的内存,这就是位(bit)。
比如:
0000:占据4位(4bit)
0000 0001:占据8位(8bit)
字节
这里就不得不提到我的上一篇编码的文章了:
了解编码(ascii,GBK,Unicode,utf-8)
最开始为了处理0和1的字符串,规定了ascii码。每一个字符为一字节,对应一串0和1,因此开始每个字符的长度也是固定的:
A:0100 0001 在内存中占了8bit。
1byte=8bit
和上一篇中对应起来,在ascii表之后出现了其他编码,01串也有变化,在现在我们通常使用的是ascii和unicode两种编码。
通常:
ascii:一个英文字母占一字节,一个汉字占两字节
unicode:一个英文占两字节,一个中文占两字节
可能由于编码原因会出现同一个字符占不同字节!!!
字
前面1byte=8bit是固定的,但是字等于多少byte呢。这个需要根据操作系统来决定,一个字占多少位,取决与总线的宽度
在16位的系统中, 1字 (word)= 2字节(byte)= 16(bit)
在32位的系统中, 1字(word)= 4字节(byte)=32(bit)
在64位的系统中,1字(word)= 8字节(byte)=64(bit)
即同一个字:
在16位中表示为0000 1000 0000 0001
在32位中表示为0000 0000 0000 0000 0000 1000 0000 0001
为什么学这个
在逆向中你会一直和底层知识打交道,这些如果不清楚的话,会让自己学的晕晕乎乎的,然后问题越积越多,让自己学不下去。
比如下面这个图,给你一个变量,你如何去确定他的地址是多少到多少,这个变量有没有溢出: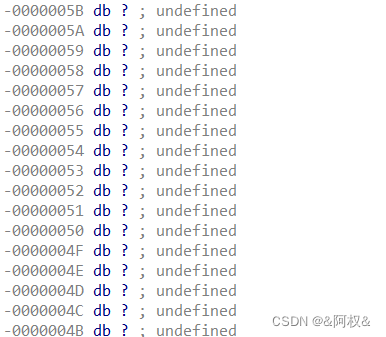
因此在逆向中,底层基础知识非常的重要