寻址帮助我们解决了数据在哪里,这里会解决数据有多大
大小端序
首先在计算机中的存储空间,我们可以抽象为这样:
每一个地址表示的单位是字节,这里从上到下为低地址到高地址。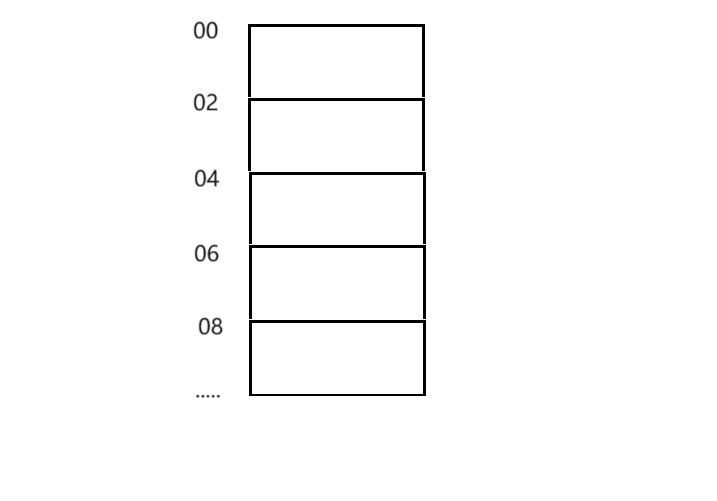
同样对于一组数据:
不论是二进制,十进制还是十六进制都可以这样理解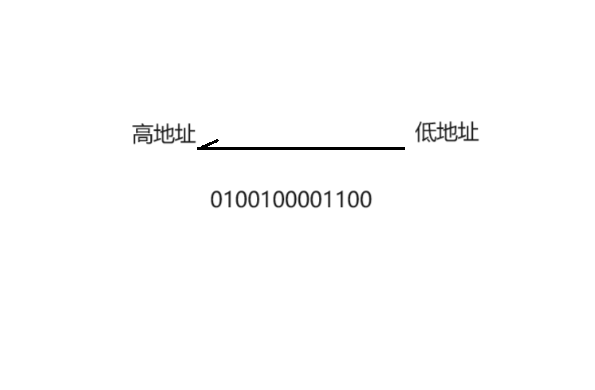
小端序:就是数据低位放在内存低位
假设我们要存储abcd四个字符,由于每一个存储单元可以放两个字节,而又采用小端序,数据低位cd放在内存低位,于是如下:
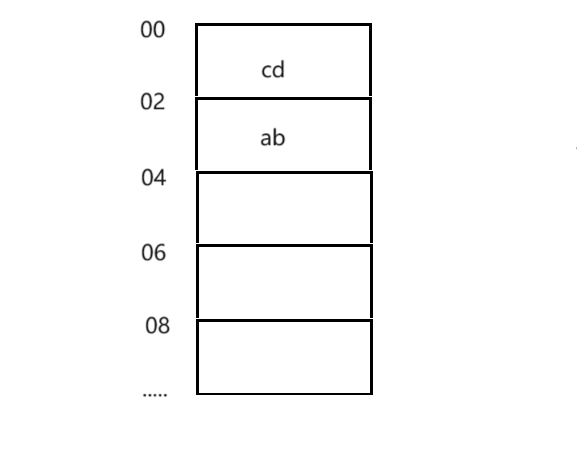
读取时内存低位放在数据低位 __cd, abcd
大端序:数据的高位放在内存低地址
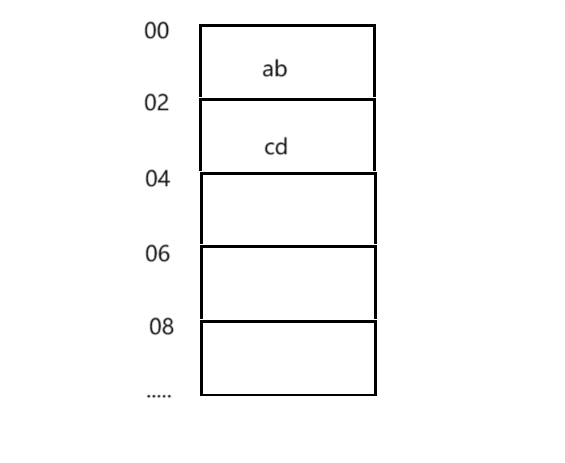
读取时低位放在数据高位,ab__,abcd
在王爽的汇编中采用的是小端序。
问题
我们在使用时,还会有汉字,特殊符号等,但是在计算机中是无法直接存储的,进过编码后占据的内存是不同的。简单来说就是我们无法确定内存00到02是一个数据,还是00到04是一个数据。
word和byte
在8086CPU中,可以处理两种数据(word和byte)。
8086的寄存器是16位的,两字节。
通过寄存器指明数据类型
1 | mov ax,1 由于ax寄存器是16位,两个字节,所以这里是字型数据 |
根据寄存器的位数确定数据的类型,将ax的数据送入bl中此类是不合法的。
通过操作符指明内存
X ptr ,X可以为word或者byte
1 | mov word ptr ds:[0],1 将字型数据1送入ds:[0]中 |
在代码中使用db,dw定义数据
上面介绍了汇编中是如何处理数据的,而我们在写汇编程序时,我们需要定义一些字符串,我们会用到db,dw
db:字节型数据
1 | db 'hello world!' |
dw:字型数据(双字节)
1 | dw 1234h |
dd:双字型数据
db,dw,dd在内存中分配的空间不同
dup指令
dup和db,dw,dd一起使用,用来进行数据的重复
| 指令 | 功能 | 相当于 |
|---|---|---|
| db 3 dup (0) | 定义了3个字节,值都为0 | db 0,0,0 |
| db 3 dup (0,1,2) | 定义了9个字节,由0,1,2重复3次 | db 0,1,2,0,1,2,0,1,2 |
| db 3dup (‘abc’,’ABC’) | 定义了18个字节 | db ‘abcABCabc..’ |
div指令
使用格式:
div 寄存器
div 内存单元
情况:除数是8位和16位数据存放的位置
| 被除数 | AX | DX和AX |
|---|---|---|
| 除数 | 8位 | 16位 |
| 商 | AL | AX |
| 余数 | AH | DX |